This is the exhibitor list for an event I was to attend. It's a very long list, and unless you recognise the name, the only way to see a little more information about each exhibitor is to click through and then back again.

I wanted to cast my eye down a list of names and brief summaries, to see who I might be interested in visiting. Obviously this information will be in the printed programme, but I don't get that until the day.
(NB this walkthrough uses version 4.2.0 which is now available. The column setup table is more intuitive in 4.2 and the ability to extract h1s by class is a new feature in 4.2)
1. Setting up the scan. It's as easy as entering the starting url (the url of the exhibitor list). There's also this very useful scan setting (under Scan > Advanced) to say that I only want to travel one click away from my starting url (there's no pagination here, it's just one long list).

There's also a "new and improved" filter for the output. Think of this as 'select where' or just 'only include data in the output table if this is true'. In this case it's easy, we only want data in the output if the page is an exhibitor detail page. Helpfully, those all contain "/exhibitors-list/exhibitor-details/" in the url, so we can set up this rule:

2. Setting up the columns for the output table. The Helper tool shows me that the name of each business is on the information page within a heading that has a class. That's handy, because I can simply choose this using the helper tool and add a column which selects that class.

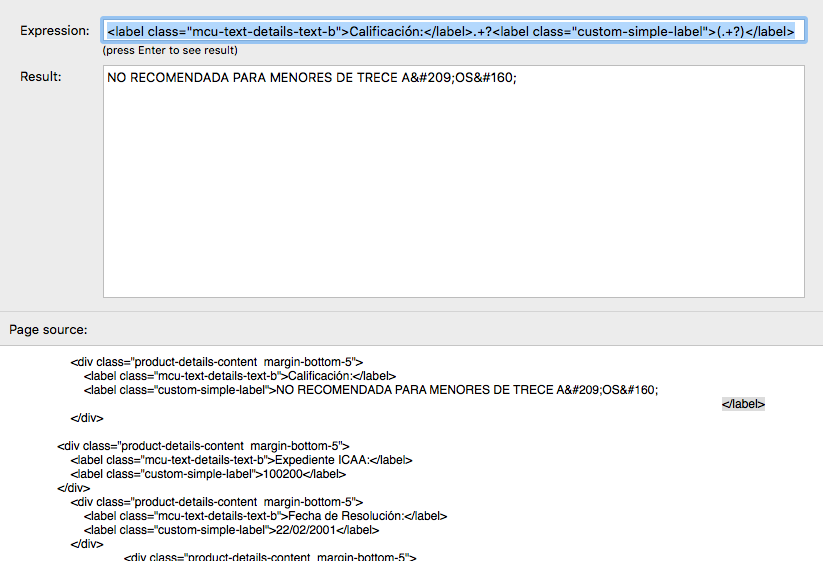
3. The summary is a little more tricky, because there's no class or id to identify it. But helpfully it is always the first paragraph (<p>) after the first heading. So we can use the regex helper to write a regular expression to extract this.
The easy way to write the expression is simply to copy a chunk of the html source containing the info you want, plus anything that identifies the beginning and end of it, and then replace the part you want with (.+?) (which means 'collect any number of any characters'). I've also replaced the heading itself with ".+?" (the same, but don't collect) because that will obviously change on each page. That is all more simple than I've made it sound there. I'm no regex expert (regexpert?) - you may well know more than me on the subject and there may be better expressions to achieve this particular job, but this works, as we can see by hitting enter to see the result.

Here's what the column setup looks like now:

(Note that I edited the column headings by double-clicking the heading itself. That heading is mirrored in the actual exported output file, and acts as a field name in both csv and json)
4. Press Go, watch the progress bar and then enjoy the results. Export to csv or other format if you like.