The default settings for Integrity, Integrity Plus, Integrity Pro and Scrutiny have been tweaked over 15 years. Generally speaking, they will be the best settings and the most likely* to perform a successful, full and useful scan.
The very short version of this post is: go with the defaults, and only adjust them if you understand and want to use an additional feature, or if you have a problem that may be cured by making a change. Please contact support if you're unsure about anything.
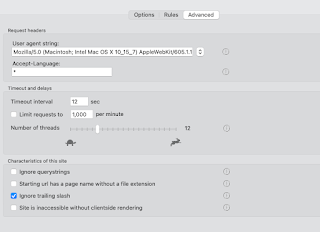
The rest of this post gives a very basic 'layman' explanation of the site-specific options and settings.
In version 12 (in beta as I write this) these settings have been rearranged and grouped into a more logical order. They're listed below as they are grouped in version 12.
Options
These are optional features. In general, only enable them (or change the default) if you understand what they mean and are prepared to troubleshoot if the option causes unexpected results.
- This page only: Simple - sometimes you may want to scan a single page. If you want to scan an entire site, leave this switched off.
- Check linked js and css files: This will drill more deeply into the site. If you're looking for a straightforward link check, leave this off.
- Check for broken images: Finding broken images is probably as important as finding broken links, leave this on
- Check lazyload images/load images: It's possible that your site uses lazyloading of images. If you know that it does then you may want to enable this. NB there is no standard for lazyloading images. Integrity will try to find the image urls in a couple of likely places, but this option can lead to false positives or duplication. Be prepared for troubleshooting.
- Check anchors: An anchor link takes you, not just to a page, but to a specific point on a page. With this option on, Integrity will check that the anchor point exists on the target page. If you know that your site uses this type of link, and you want to test them, enable this option.
- Flag missing link url: Sometimes during development, you'll create links with empty targets, or use # as a placeholder. This is a way to find those 'unfinished' links.
Advanced
Here we have the controls that may sometimes need to be altered to 'tune' Integrity to your site. In general, the default values should work, only change them if you have a reason.
- User-agent string: The default values should work almost all of the time. If the user-agent string is how Integrity identifies itself. If this is set to that of a real browser (which is now the default value) then that should be fine. (Occasionally a site will give different pages for a mobile browser / desktop browser. Or to Googlebot.)
- Accept language: can be used to check specific language pages of a multilingual site.
- Timeouts and delays: Use the defaults. If you have problems with timeouts or certain errors then it may be necessary to adjust these settings.
Site characteristics
Here are a few settings which may need to be adjusted for your particular site. Again, the defaults should be fine, but refer to this guide or ask for help if you have problems.
- Ignore querystrings: This is the option that is most likely to need changing to suit your particular site. The default is off and that'll probably be fine. However sometimes a session id or other things can be included in the querystring (the part after the ? in a url.) and sometimes these can cause loops or duplications. In that case the setting should be on. On the flip side, sometimes important information can be included in the querystring, such as a page id, and so for those sites you definitely need the setting to be off.
- Page urls have no file extension (more recently renamed 'Starting url has page name without file extension'): The explanation of what this box actually does is lengthy and it's more than likely that you don't need it switched on. In the case where it's required, Integrity should recognise this and ask you an explicit question, and set this box accordingly.
- Ignore trailing slash: It's very unlikely that this needs to be switched off (default is on). It has become less important in version 12 because its inner workings are slightly different.
If you're using version 10 or earlier, then you'll have the option to Check links on error pages. I strongly advise leaving this switched off, as it's pretty likely to cause problems or confusion. v12 doesn't have the option.
If you have a custom error page (which is likely to be one page) and want to test the links on it, then test it separately by setting up a single-page configuration to a non-existent url (such as mysite.com/xyzabc)
Rules
If you have a specific problem, then you can sometimes cure that with a targeted 'ignore' or 'don't check' rule.
The other very useful use for rules is to either ignore an entire section of a site, or to limit the crawl to a specific part of a site.
*It may not seem that way if yours is one of the sites that needs a change from default settings, but that's probability for you. In practice, only the querystring setting is an unpredictable 'it depends' setting. Go with the default, contact support if you need help.