

Toggle to 'Complex setup' if you're not set to that already.
Add a column to the output file and choose Regular expression. Then use the helper button (unless you're a regex aficionado and have already written the expression). You can search the source for the part you want and test your expression as you write it. (see below). Actually writing the expression is outside the scope of this article, but one important thing to say is that if there is no capturing in your expression (round brackets) then the result of the whole expression will be included in your output. If there is capturing (as in my example below) then only the captured data is output.
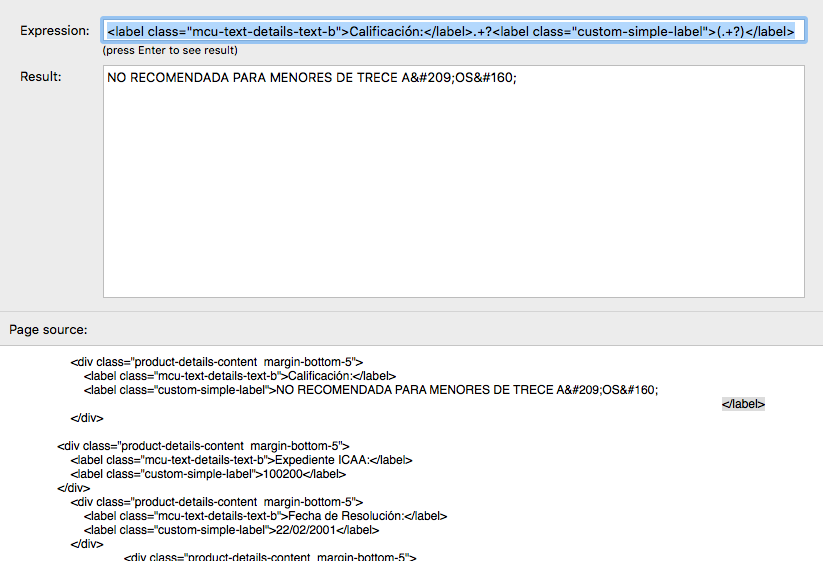


5. If you limited the links while you were testing as I did, remember to change that back to a suitably high limit (the default is 200,000 I believe) and set your starting url to the home page of the site or something suitable for crawling all of the pages you're interested in.
As always, please contact support if you need more help or would like to commission us to do the job.
* as I write this, webscraper checks for class, id and itemprop inside <div>, <span>, <dd> and <p> tags, this is likely to be expanded in future.
No comments:
Post a Comment