Back in April we launched version 12 of Scrutiny (skipping 11).
Since then the topic of structured data has been raised by users.
Scrutiny has long collected Twitter and open graph meta data, and has displayed those fields in its SEO > Meta Data table. But not structured data provided via json-ld.
It's easy to collect this but not so easy to display it en masse as it has a 'tree' structure.
Here are some first steps. I'm open to discussion on where to go from here. The following is all possible with the current version of Scrutiny, 12.5.0
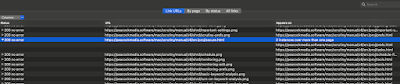
The json-ld is collected from each page and parsed. Perhaps the most important pieces of information are the @types. Like headings there may be multiple, and at different levels, so like headings they can be displayed in the table, in a single column using a separator and in the order that they appear.
The column can be switched on using the Columns selector above the SEO > Meta Data table
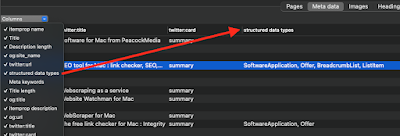
That allows you to see at a glance what pages have the structured data and what type(s) are used.
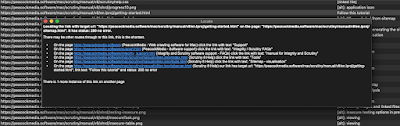
For more detail on a particular page, a double click in this table opens the Page Inspector:
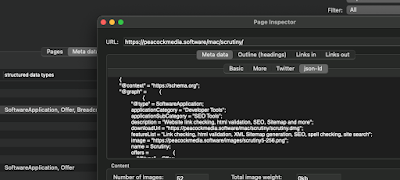
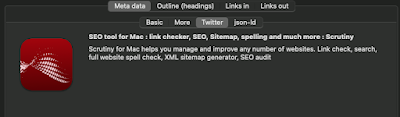
This is the Meta data > json-ld tab of the Page Inspector. Note that we're not seeing the original json string from the page. It has been parsed and formatted. It's the way that a machine would read it, and if Scrutiny can't read the json, then there will be an error message here. (You can see that I've used @graph here in order to display both the software application and the breadcrumb list within the same chunk of json-ld. If there are multiple chunks of json-ld on the page then they'll be amalgamated here.)
Also in the same inspector is a Twitter Card viewer. This will display information from the Twitter meta data if present, and fall back on Open Graph (og:) fields, as Twitter does. This doesn't look exactly the way that Twitter would display the information - Twitter also draws on info from the Twitter account referenced.